

There are only two hard things in Computer Science: cache invalidation and naming things.
– Phil Karlton
CSSRooster is here to alleviate programmers from the second one – naming things, more specifically, writing class names to HTML tags.
How does it work? CSSRooster takes your HTML code as input, including CSS styles, and then writes class names for your HTML tags by analyzing the patterns hidden in your code. Since you would not want to leak any class names in your HTML code (otherwise, CSSRooster can just cheat, although in fact he will just ignore it), there are two ways for you to associate styles: Method 1, just inline all styles. Method 2, use some random characters as class names that would not leak any information of the underlying DOM element. An example below (note that only webkit based browsers are supported for running the examples):
Just like how every new parents name their beloved babies, they need to know if they are boys or girls, are they naughty or quiet, so and so. The same goes with CSSRooster, who has access to all the visual and semantic properties of a DOM element. It learned the top 1000 sites on the Internet on how they give class names to various elements. With this knowledge he can make some really informative guesses. Click on the "ASSIGN CLASSES" button above if you haven't and see the class names wrote by CSSRooster.
We can see that CSSRooster successfully learned to give class names such as title, list, item, icon, etc. It knows that an item usually don't go alone, and usually has a list parent. It also knows a common pattern in the front end engineer's toolbox, use an <i> as an icon within a link.
Another thing worth noting is how CSSRooster gives the class button to a link but gives link to the others. The following is the rendered result of the the code above.
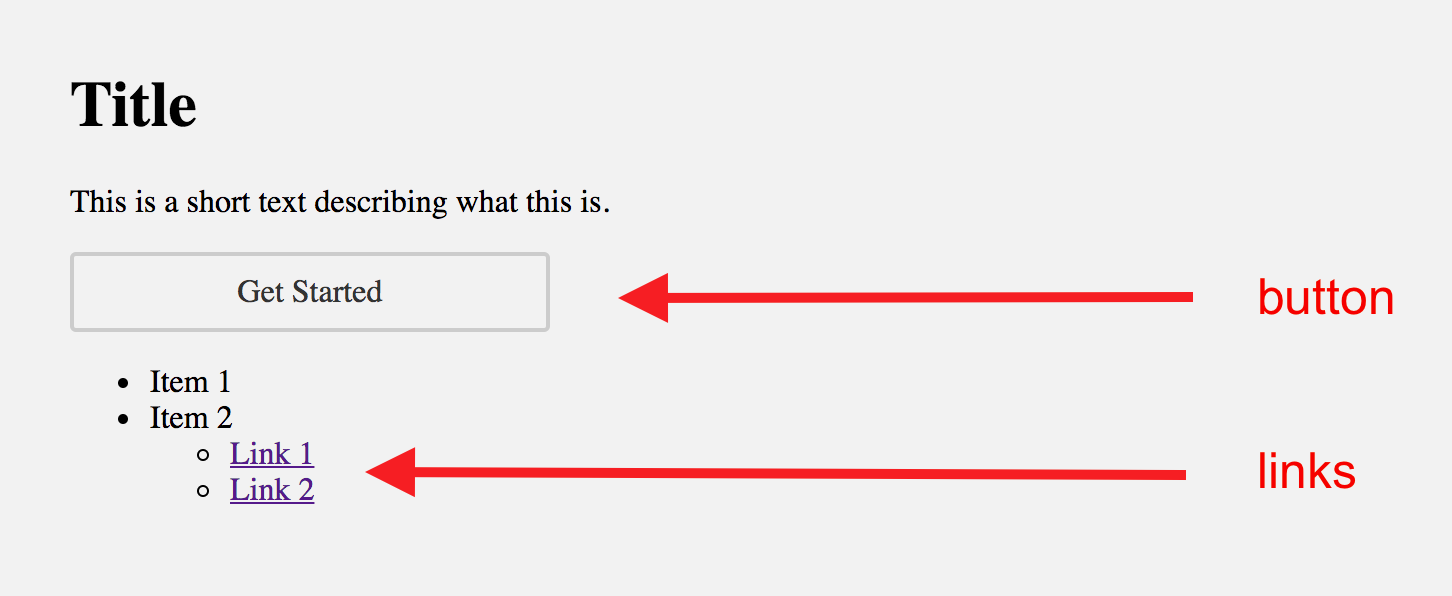
As you can see, CSSRooster successfully learns to recognize the first <a> element as a button and the ones below as links. We human beings definitely know when an <a> element is a button and when it is a link. CSSRooster does this in a similar way, you can try to slice out some of the CSS properties such as border to make the button look more like a link. And at some point, CSSRooster will notice that this is not a button anymore and possibly assign link to the element. You might want to ask, what are the properties that CSSRooster thinks make a button, well, the answer is I don't know, it's all learned from the data, so whatever the data says :)
The following example is a signup form of Ebates.
The rendered version:
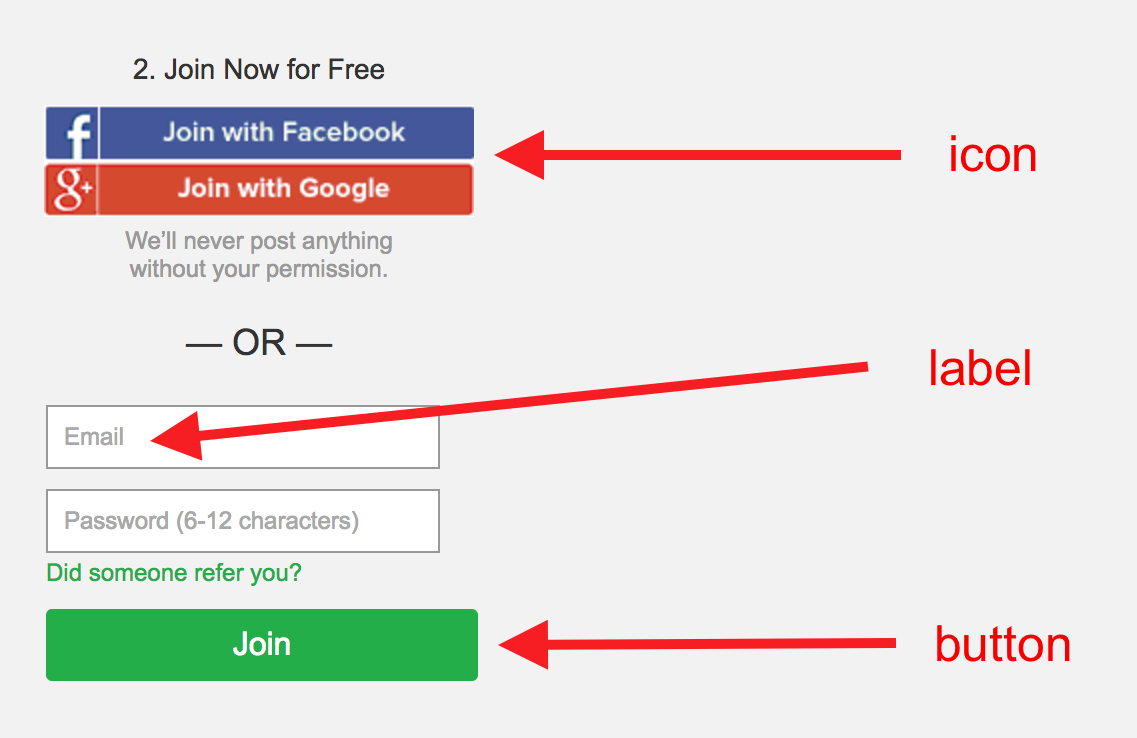
One thing very interesting about this example is the the "Join with Facebook" and "Join with Google" "button"s. The author of Ebates, they actually put icon on these two "button"s, which kind of makes sense since they are actually just two images – the old fake button trick people use before CSS3 support becomes prevalent, But they actually act as buttons, and the model correctly recognizes that, by leveraging knowledge learned from other web page authors!
This Rooster is still very young though. From the example above, we see that it recognizes the <label><input> pattern in HTML forms by correctly assigning label class to the <label> element. But it fails to guess what the text input is. There might be several reasons. For one, data noise, which is a common culprit for a lot of real world deep learning problems. For example, for class names, different authors might have different preferences, some of them call a button as button where others might call btn. Even for the same button, one might set its background as black, the other might set it as red, one might have box shadow, the other might have no shadow at all. So the biggest challenge of the model is how to find an average out of all these different types of front end engineers who are from very different cultures. The same goes with HTML forms, which is very tightly bound to the specific business of the website, so the pattern there is even weaker and CSSRooster doesn't know what to do with it. Another possible reason is due to unbalanced training data. If you do a quick mind search, you would notice that you mostly only see 2-3 text/password fields per landing page, whereas much more text/boxes and the mostly invisible divs. This issue is solvable by using a more advanced sampling technique though, which is one of the future work of CSSRooster.
What's CSSRooster's role in Huula? It's going to be a part of Huula intelligent designer (try it out here). With CSSRooster, we can automatically apply conventional styles to an undesigned/lightly designed web page and get it ready for launch or further tweaks. It will also make it easier for users to select similar elements and style them all at once. Since the data Huula receives already contains all the styles, but the class name might be very badly designed, so it's not easy to perform something like 'select all menu items'. But with CSSRooster, we can just feed the site data to the model and have the page 'normalized', then the page will have all the menu items categorized together for your selection.
Now, it's your turn! Play with it with your HTML code and let us know your thoughts on twitter @huulaofficial.
As some folks are asking the model details. I'll briefly explain it here. CSSRooster's brain consists of an embedding layer for class names, a convolution layer (with max pooling) and an LSTM layer and projection layer. A very conventional model. It was trained for about 3 days on a Core i7 MacBook Pro (yeah, I know, the fan screams quite a bit, but our GTX GPU is on the way!).
Side note: why is this thing called CSSRooster? Coz it's 2017 – Fire Rooster Year!
Presented by Huu.la - UI design + AI.
01/30/2017